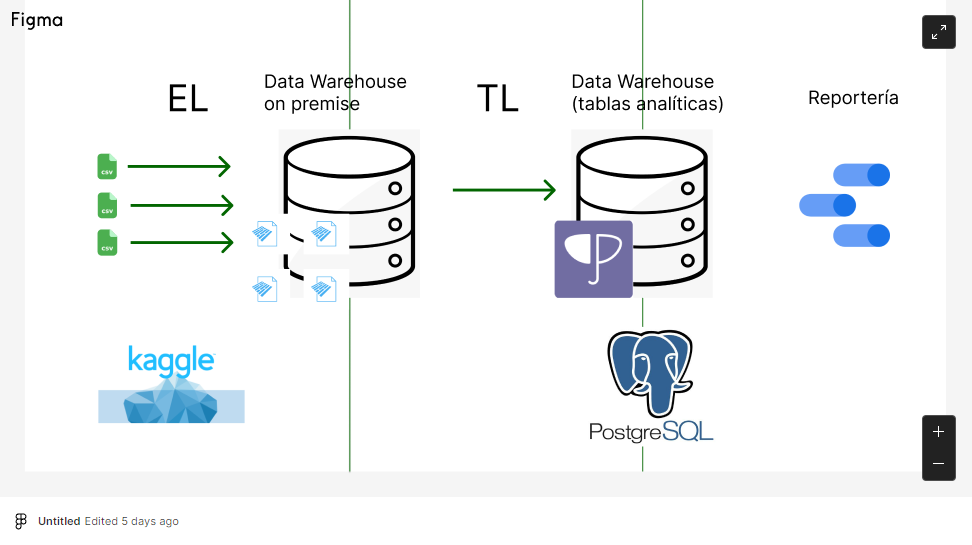
Pipeline
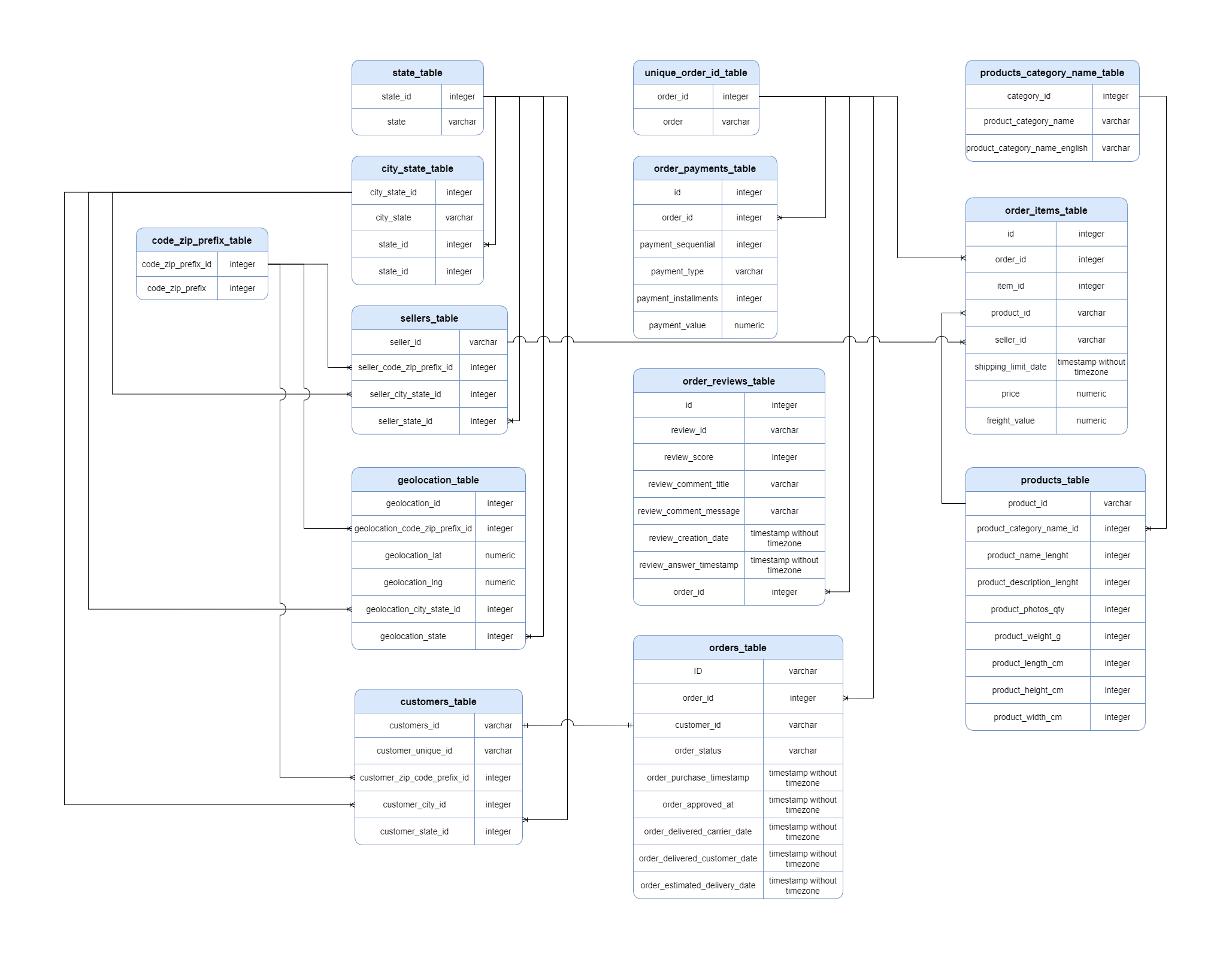
Original data was divided in 9 tables, in the next structure:
We apply an ETL process. Starting with the API of Kaggle to extract the data. Using python scripts to clean and transform data. Finishing with the load on a PostgreSQL DataBase deployed in Heroku for future use in Google Data Studio. For a detailed explanation you can consult:
- Our Github Repository to see the intial exploration and cleaning
- Pipeline Repository to see the ETL automatic process
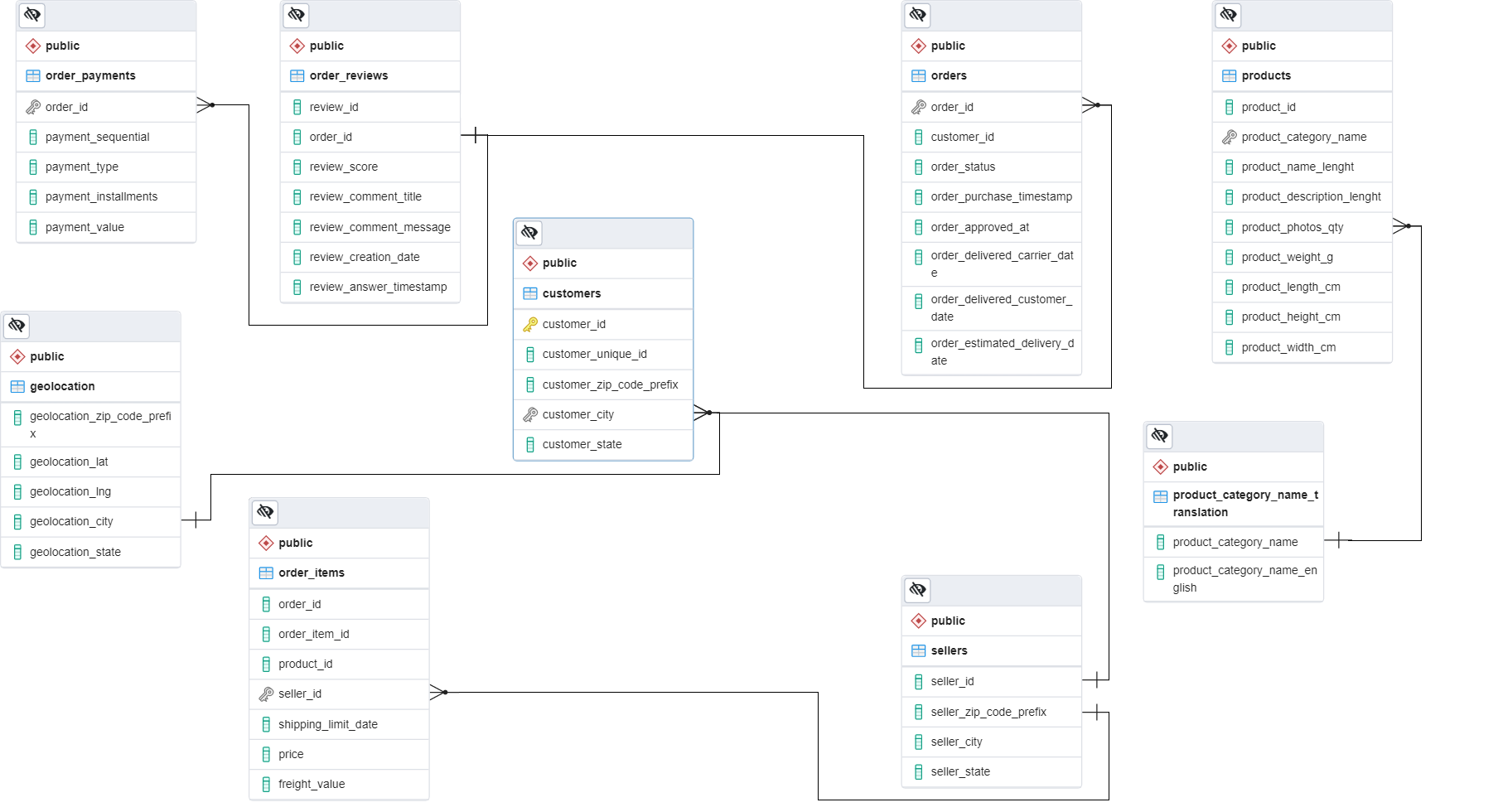
After ETL, our Database ends with the next structure: